数据科学平台是面向数据存储、数据获取、模型训练、模型部署以及结果预测一体化的一款大数据挖掘产品,该平台能够通过对大规模数据集的处理,提高数据处理效率,依据机器学习、深度学习模型进行模型训练,帮助用户提供准实时的建模能力,当面对数据碎片化和数据隔离时,通过加密机制下的参数交换方式建立虚拟的共有模型,在充分保障各个参与方的隐私信息和数据安全的同时,多方联合建模满足对特定的业务场景数据分析的需求。
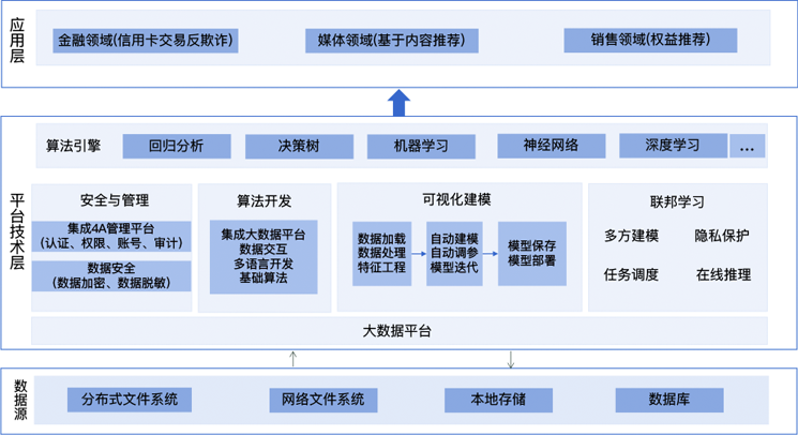
基于Hadoop分布式文件系统,有效处理超大规模数据集,具有稳定性高、可扩展性强的特点,并结合spark框架进行分布式数据预处理和算法实现,提供准实时的建模能力。
内置多种算法模型,可在页面进行点击操作完成数据处理、算法选择,通过对模型的调用输入参数的配置,实现模型训练。
通过准确率、召回率等指标来评价算法的效果;通过参数优化、算法调整等方式改进模型效果。
内置联邦学习,支持同态加密、SecretShare、DiffieHellman等多方安全计算协议,法律合规认证,大幅降低数据合作壁垒。
在联合建模过程中,各个参与方依据贡献度获取建模收益,对恶意参与方的数据和模型作弊行为可检测可抵御。
数据科学平台用户登陆使用LDAP用户登陆,基于LDAP可作为数据库的特点,通过目录结构的方式存储用户信息来响应用户查找需求。
通过对PySpark与Scala内核的安装,实现启动内核环境时自动接入大数据平台,使用集群资源。
数据科学平台支持常用的Python,R,Scala编程语言,通过在页面上点击新建可实现指定语言的使用。
在建模的同时,终端用户可视化和度量模型训练的全过程,支持对模型训练过程全流程的跟踪、统计和监控等,提供模型运行状态、模型输出和日志等信息。
平台支持逻辑回归、线性回归、k-means、PCA、SVM等模型,支持神经网络训练,无监督学习,通过参数的调优实现模型最优化。
人工智能Pipeline调度平台致力于完成高弹性、高性能的学习任务,主要包括模型训练、模型管理、生产发布以及联邦建模过程中输入输出实时跟踪等。
解决代码中的依赖模块缺失问题,可在平台提供的页面进行命令行安装以及自定义编程函数式安装。
提供Kaggle比赛机器学习项目案例,提供样例数据。
关注我们
Copyright © 2018 丨Hong Kong Zhonghao Technology Co, Ltd. 香港中昊科技有限公司京ICP备19005201号 京公网安备 11010702001841号 

请使用IE8及以上内核浏览器,建议使用Chrome、Firefox、360最新版等














